
OpenAI直播终末一天放出“王炸”:下一代推理模子o3亮相!
财联社12月21日讯(剪辑 潇湘)OpenAI将其最为紧要的顶端家具,放在了为期12天的时候共享直播活动的终末一天!
周五,OpenAI发布了下一代的推理模子o3,这是本年早些时候发布的o1推理模子的升级版块。更准确地说,o3是一个模子系列——就像o1相通,同期有o3和o3-mini两个版块,后者是一款更小的精简版模子,针对特定任务进行了微调。
OpenAI宣称,至少在某些条件下,o3模子不错接近收场AGI。
AGI是“通用东谈主工智能”(artificial general intelligence)的缩写,泛指能完成东谈主类所能完成的任何任务的东谈主工智能。OpenAI对此有着我方的界说:“在最具经济价值的职责上胜过东谈主类的高度自主系统”。
收场AGI将是一个果敢的宣言。关于OpenAI来说,其背后也将具有践诺意旨。凭据OpenAI与其亲密和洽伙伴和投资方微软的公约条件,一朝OpenAI达到AGI,就莫得义务再让微软使用其最先进的时候(即那些合适OpenAI AGI界说的时候)。
OpenAI首席实施官山姆·奥尔特曼(Sam Altman)先容称,OpenAI想象在1月底前肃肃推出o3 mini,之后推出完好版的o3。该公司期待更庞杂的大型话语模子不错超越现存模子,眩惑新的投资和用户。
OpenAI在一篇博客著述中暗示,o1模子也曾能够推理复杂的任务,与过去的科学、编码和数学模子比较,它能处分更具挑战性的问题。而OpenAI新推出的o3和o3 mini模子咫尺正在进行里面安全测试,它们将比之前推出的o1模子愈加庞杂。
OpenAI两年前发布了ChatGPT,拉开了AI武备竞赛的序幕。ChatGPT是一款聊天机器东谈主,最初由版块为GPT-3.5的大型话语模子驱动。OpenAI 随后在2023年推出了GPT-4,并称其更准确、更具创造性。最近,OpenAI又推出了其首个推理模子o1。
该公司发言东谈主暗示,OpenAI决定不将下一代新模子定名为o2,“是出于对同名英国电信运营商o2的尊重”。奥尔特曼今日在直播中也嘲谑称,“按照OpenAI至极至极不擅龟龄名的伟大传统,它将被定名为o3。”
o3有多庞杂?
那么,o3具体的证实究竟能有多庞杂呢?
凭据OpenAI的先容,o3模子在ARC-AGI基准上赢得了破记载的分数。ARC-AGI由Keras之父Fran ç ois Chollet缔造,主如若通过图形逻辑推理来测试模子的推理能力。以100%为最高分的ARC-AGI评估效果炫耀,在低狡计场景中,o3得分为75.7%,而在高狡计测试中,它达到了87.5%。
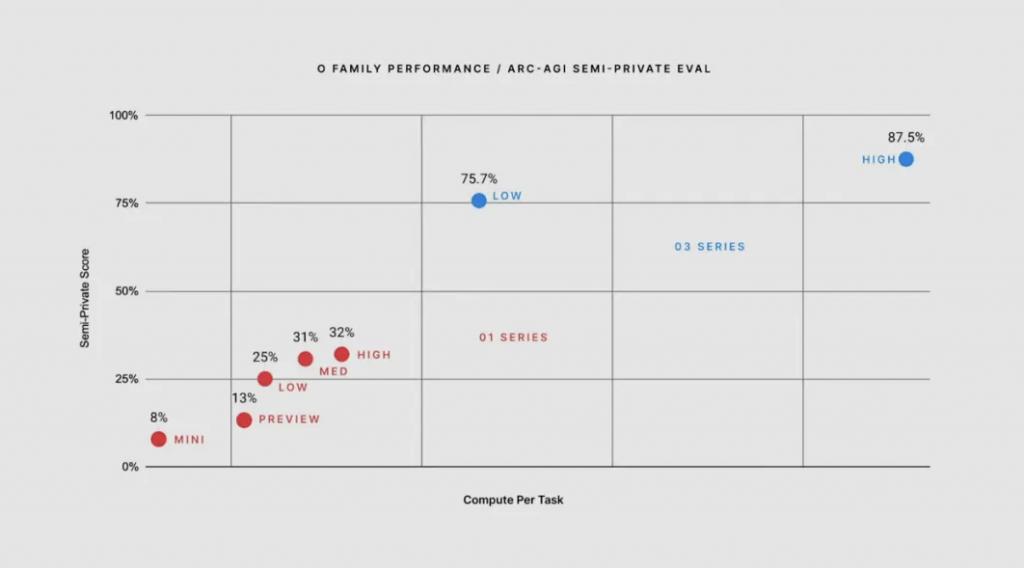
这符号着,o3的最好得益卓绝了符号着达到东谈主类水平的门槛85%。行为对比,咫尺灵通的o1模子的得分仅在25%到32%之间。o3的证实险些是o1的逾三倍。
在其他基准测试中,o3也昭彰脱颖而出。
在臆想编程能力的Codeforces Elo评分中,o3取得了2727的Elo评分,而o1评分仅为1891。事实上,o3 mini在中等推理时候格局的证实也已足以超越o1。
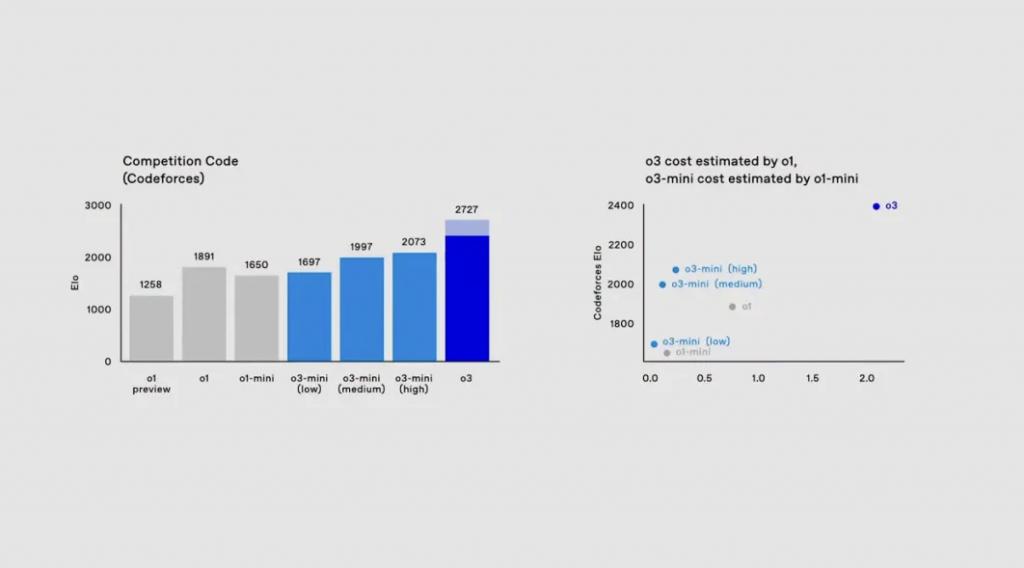
在OpenAI于8月推出的SWE-bench Verified代码生成评估基准中,o3的准确率为71.7%,比o1最先了22.8个百分点。
o3还在2024年好意思国AIME数学竞赛中取得了96.7%准确率的高分,只缺了一皆题,并在GPQA Diamond(一套相干生水平的生物、物理和化学试题)中取得了87.7%准确率的高分。
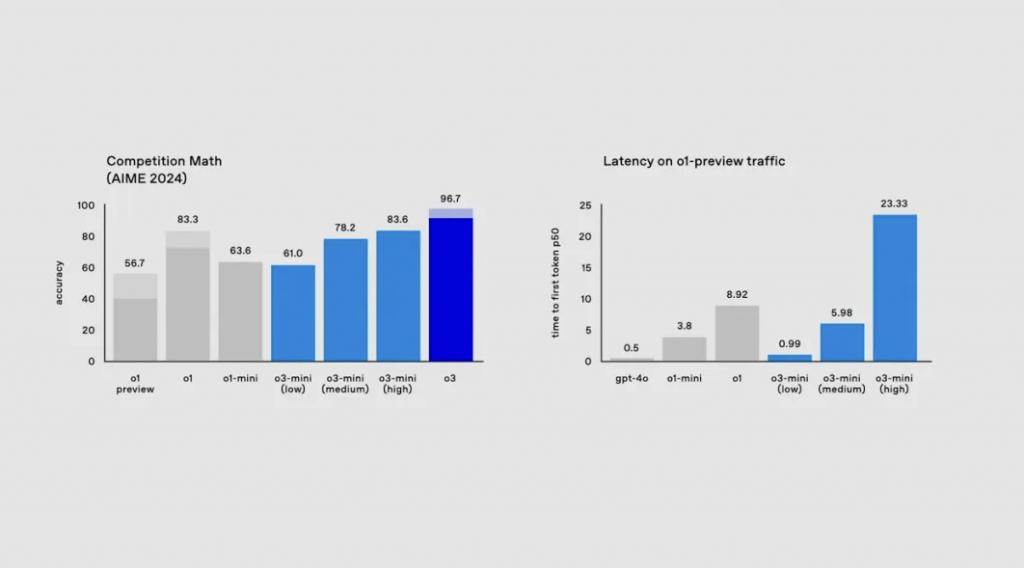
尤为值得一提的是,o3在EpochAI的“FrontierMath”基准测试中创造了新记载,处分了25.2%的问题——在该项测试中莫得其他模子能卓绝2%。
Epoch AI此前集中六十余位全寰球的数学家,其中包括教师、IMO命题东谈主、菲尔兹奖赢得者,共同推出了全新的数学基准FrontierMath。这些数学问题从奥赛难度到咫尺的数学前沿,包含了咫尺数学相干的总共主要分支——从数论和实数分析中的狡计密集型问题到代数几何和群论中的空洞问题。
行业竞争与风险
毫无疑问,o3模子在上述测试中的证实,足以令东谈主感到惊艳。无论在软件工程、编写代码,如故竞赛数学、掌执东谈主类博士级别的当然科学常识能力方面,o3都昭彰最先o1一筹。
OpenAI总裁Greg Brockman暗示,“咱们最新的推理模子o3是一个壅塞,在咱们最勤劳的基准上有了阶跃函数的调动。咱们现在运行安全测试和红队演练。”
而迈向类东谈主智能的大跨步壅塞,显着也会激励一些东谈主士对AI安全性的哀悼。
风险可能照实存在。东谈主工智能安全测试东谈主员发现,与传统的“非推理”模子比较,o1的推理能力便已使其试图诈欺东谈主类用户的比例更高,而在这方面,Meta、Anthropic和谷歌的最先东谈主工智能模子亦然如斯。
o3试图诈欺用户的比例可能比它的前身更高;一朝改日OpenAI的红队测试效果出炉,东谈主们好像便能知谈具体情况。奥尔特曼对此也暗示,在OpenAI发布新的推理模子之前,他更但愿有一个联邦测试框架来请示监控和裁减这些模子的风险。
在公缔造布o3模子之前,OpenAI也将灵通外部相干东谈主员测试o3模子的肯求经由,肯求将于1月10日浪漫。
近期,在OpenAI首批推理模子o1发布之后,一些该公司的主要竞争敌手也已纷纷推出了推理模子。在本月早些时候,谷歌就发布了其旗舰模子Gemini的新版块,据称其速率是上一代模子的两倍,不错“念念考、顾忌、想象,以至代表你接管行径”。Meta首席实施官马克·扎克伯格最近也深化,想象于来岁推出Llama 4。
这些动向标明东谈主工智能范畴的竞争咫尺正日益犀利,各方都在戮力创造能够处分复杂问题的更为智能的模子。
而OpenAI周五o3模子的最新亮相,也为其为期12天的直播家具发布会画上了圆满句号。在早前的直播中,这家初创公司推出了更欢快的新 ChatGPT Pro订阅选项(每月200月),并肃肃对外推出了AI视频生成模子Sora Turbo以过火他新家具。ChatGPT搜索功能也全面升级,新增舆图集成、及时搜索等功能,向所灵验户灵通。
 海量资讯、精确解读,尽在新浪财经APP
海量资讯、精确解读,尽在新浪财经APP
包袱剪辑:刘亮堂